
About 10% of Americans now turn to AI chatbots for news at least sometimes—and among news consumers under 25 worldwide, this share gets closer to 15%. Yet trust is running ahead of reliability. About half of U.S. adults who get news this way reported encountering information they believed to be inaccurate, and about a third struggled to separate true claims from false. As AI quietly assumes the role that search engines once held, increasingly selective and increasingly trusted without a click-through to a source, a natural question emerges: How reliable and trustworthy are AI chatbots in answering questions about events unfolding each day?
In a new preprint study, we evaluated six commercial AI chatbots on 2,100 same-day news questions, yielding 12,600 model responses, across six regions and languages. We found that while many achieved over 90% accuracy on multiple-choice questions, the aggregate scores obscured three crucial patterns that bear directly on whether these systems can be trusted as news intermediaries: a regional accuracy disparity that concentrates on Hindi, citation profiles shaped by retrieval-and-synthesis engineering and legal considerations, and a sharp loss of robustness whenever a question’s premise is slightly off.
A Significant Advance, But Unevenly Distributed
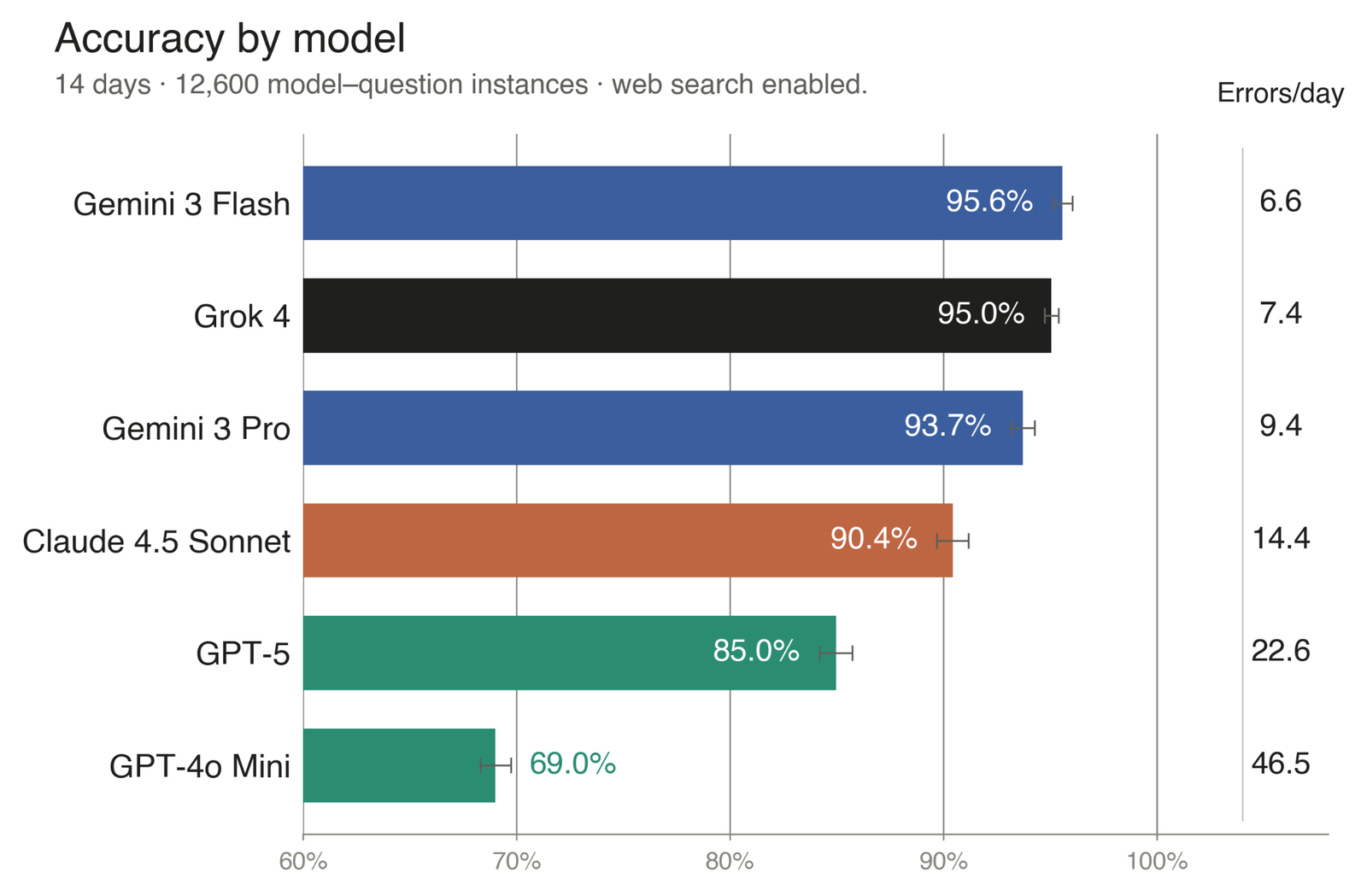
During a 14-day evaluation (February 9-22, 2026), we posed 25 multiple-choice questions per region each day (150 distinct questions daily) to each of six user-facing commercial AI chatbots. Each day, we generated questions from same-day BBC News reporting in six regional services (U.S. & Canada, Afrique, Arabic, Hindi, Russian, Turkish), targeting article-specific details (such as exact figures, named sources, locations, and times, etc.). The top systems (Gemini 3 Flash at 95.6%, Grok 4 at 95.0%, and Gemini 3 Pro at 93.7%) answered correctly more than nine times out of ten. This represents a meaningful improvement over earlier real-time question-answering benchmarks such as RealTime QA.
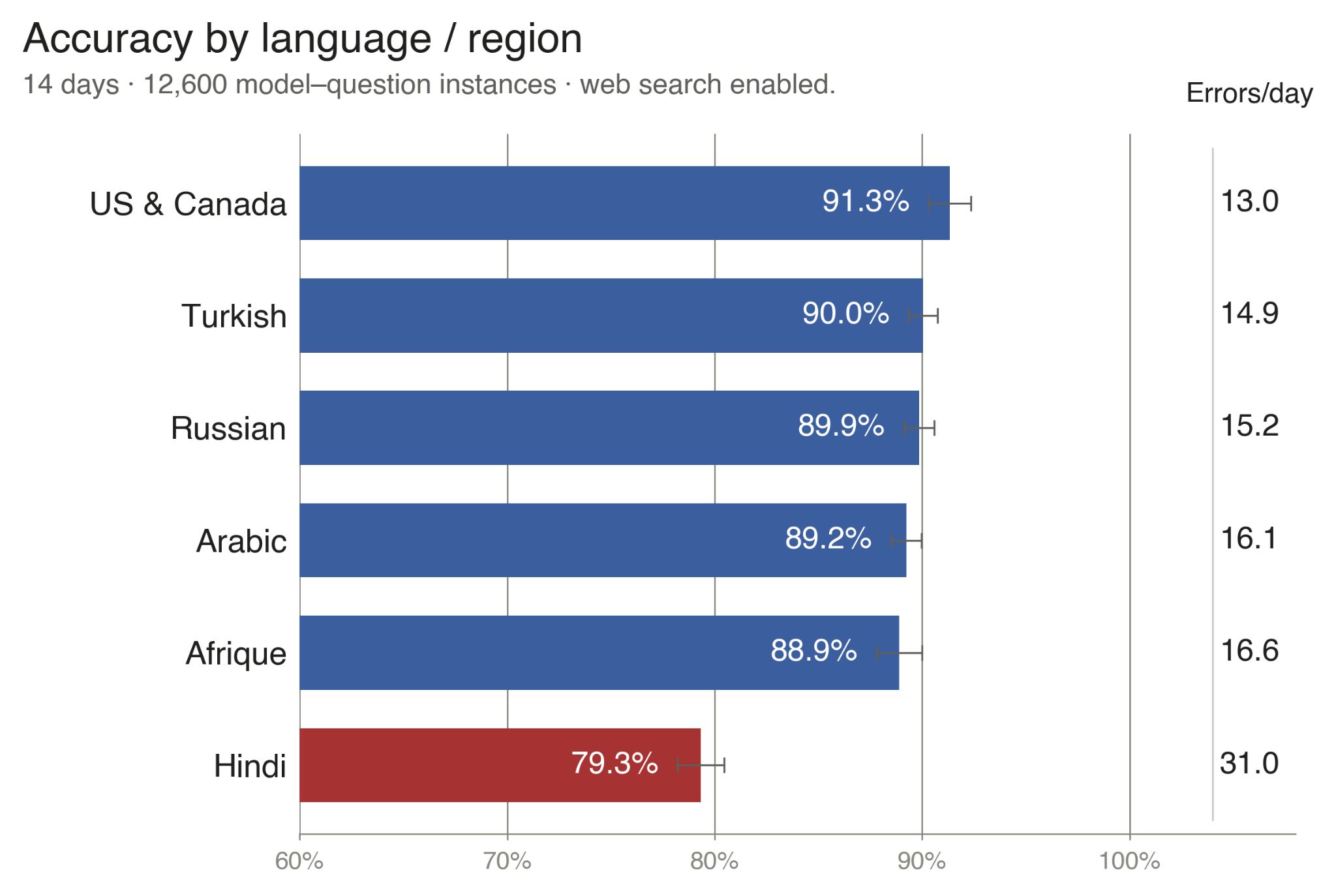
But the aggregate accuracy obscures whom this capability serves. Five of the six regional services cluster tightly between 88.9% and 91.3%, but the average Hindi performance is at 79.3%, nearly 10% below the next-lowest region. Every model tested performed the worst in Hindi. Hindi has roughly twice the error volume of any other region. And even excluding GPT-4o-mini (the lowest-performing model), the five strongest systems still produce error rates of about 16% in Hindi, compared with 5–8% in the other five regions.
 Retrieval, Not Reasoning, Drives the Errors
Retrieval, Not Reasoning, Drives the Errors
To move from error rates to error mechanisms, we classified all 1,497 wrong answers into eight categories using three LLM annotators. Two categories dominated, accounting for over 70% of all errors. Retrieval failure, in which the model cannot locate sufficiently relevant content, accounted for 38.8% of errors. Source divergence, in which the model retrieves a thematically related but factually distinct source and answers from that substitute, accounted for 32.7%. The remaining six categories altogether constituted less than 30%. We observed that when models retrieved a correct source, they almost always extracted the correct answer. The bottleneck was therefore the connection between query and evidence, not the reasoning that followed.
This pattern helps us reframe the Hindi gap. The failure is not one of language comprehension. These systems read Hindi fluently and reason competently in it. It is a failure of evidence binding: When the retrieval pipeline cannot surface the target Hindi article, it returns an English-language source covering the same broad topic, and the model answers from that substitute with no or limited indication that the source has shifted. This is most salient in the citation data. For Hindi-language queries, the single most-cited domain is English Wikipedia, which surpasses every Hindi-language news outlet on the index. In one error documented in the appendix, a model asked about the share of Indian merchant mariners in the global workforce (for which the BBC Hindi article reported 7%) retrieved an English-language industry portal stating the globally circulated 10–12% figure, and answered 10%. The same pattern recurs, in milder form, across most non-English regions.
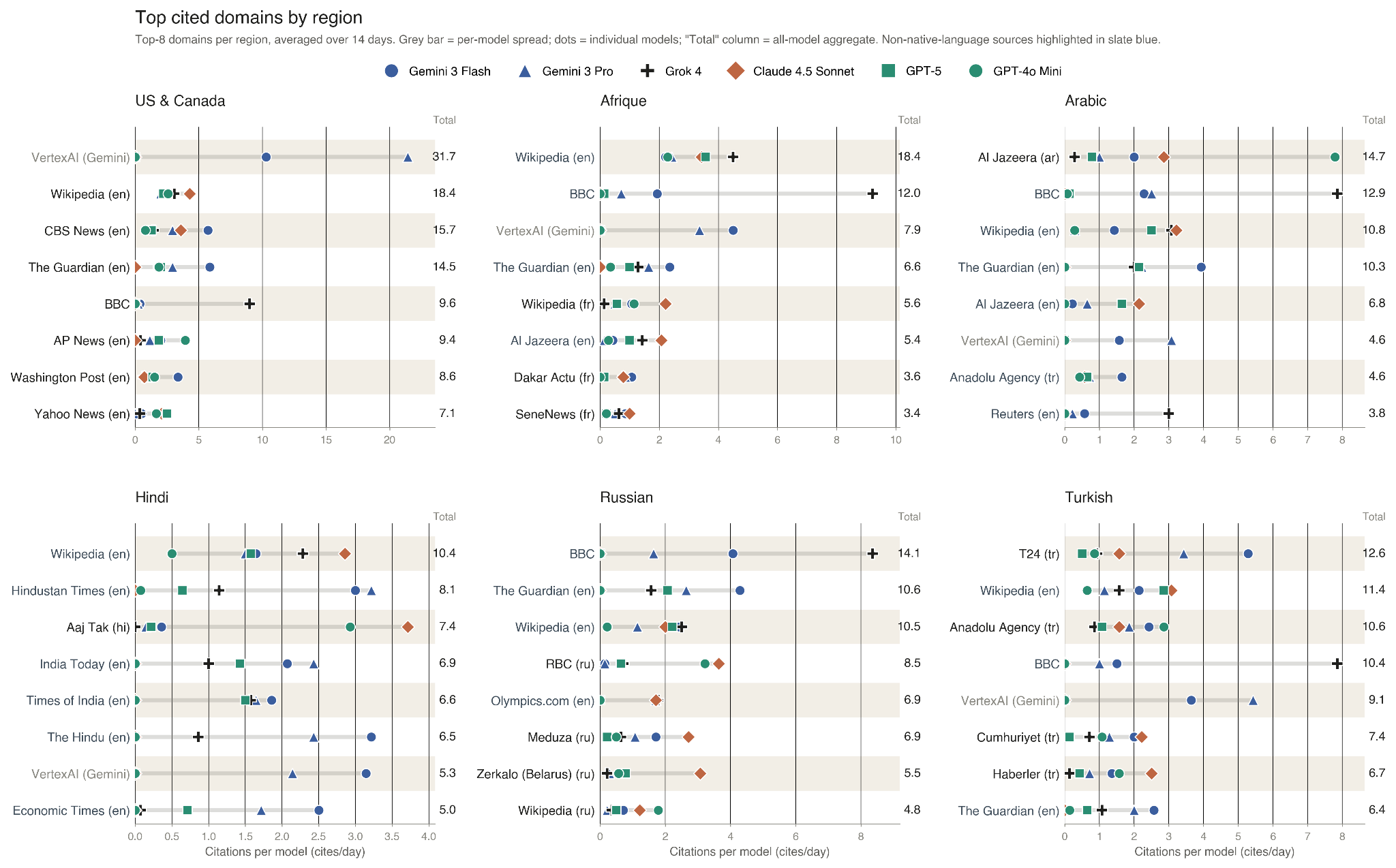
 What the Citations Reveal
What the Citations Reveal
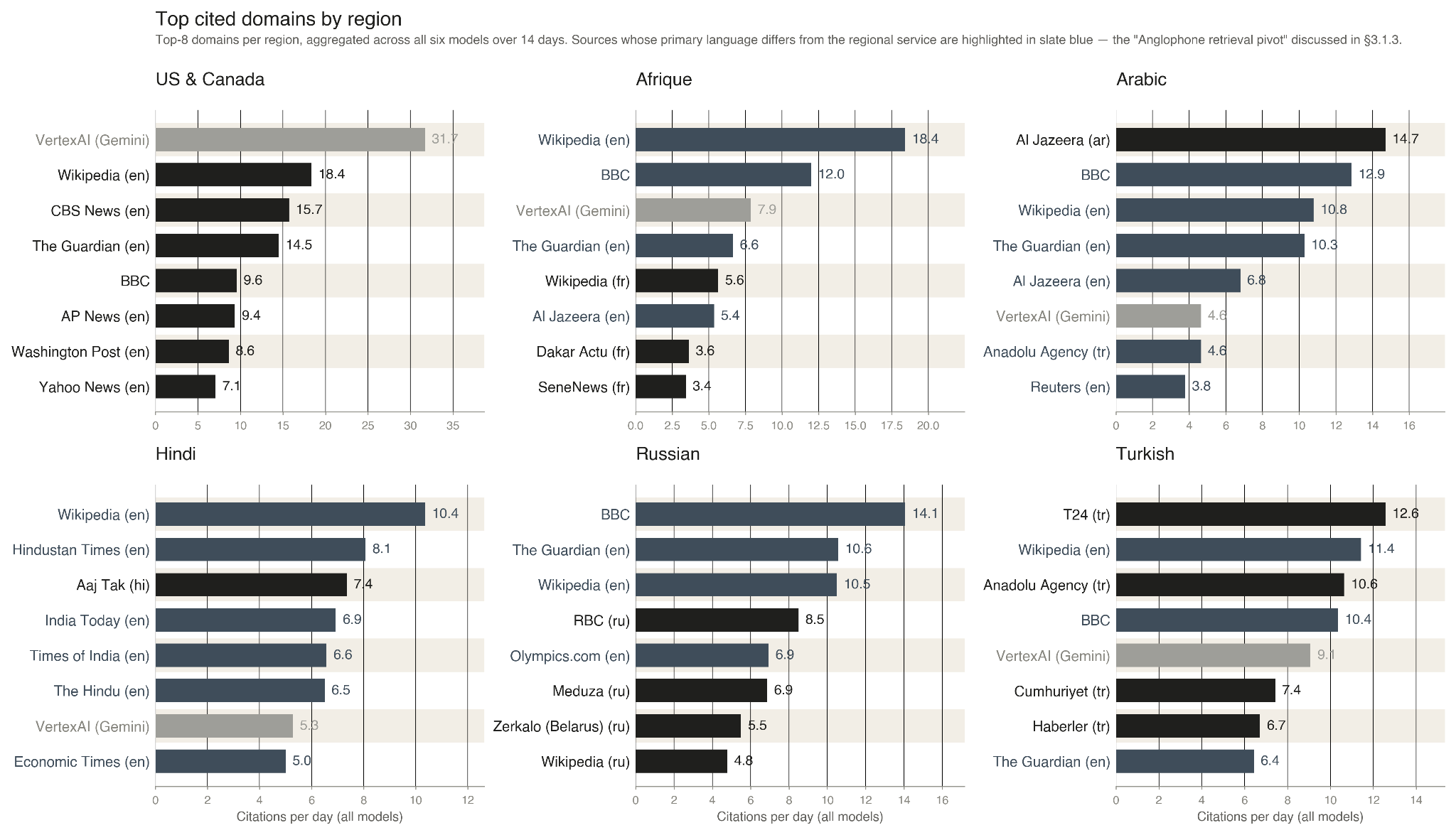
We also analyzed every URL cited across all 12,600 model responses. Two patterns stood out.
First, Grok 4 cited BBC News at high rates: 28.5% of its responses included a BBC URL (even though there is no publicly known partnership between Grok and BBC). Three of the other chatbots virtually never cited BBC (Claude 4.5 Sonnet 0.0%, GPT-4o-mini 0.0%, GPT-5 0.2%), while the two Gemini models did so occasionally (Pro 4.1% and Flash 6.9%). The divergence almost certainly reflects scraping policy and licensing compliance as much as retrieval capability: The BBC has actively enforced robots.txt restrictions and threatened legal action against AI companies that scrape its content without authorization. Providers that comply will mechanically cite the BBC less, regardless of how well their retrieval works. Grok 4’s higher rate may reflect a more aggressive crawling posture rather than a better retrieval infrastructure.
Second, the models relied heavily on English-language sources even when answering questions about non-English news. Of the six BBC regional services we evaluated, only U.S. & Canada publishes in English. Yet across the full study, nine of the ten most-cited domains were primarily English-language, and English Wikipedia was the single most-cited source overall. Indeed, English Wikipedia ranked among the three most-cited domains in all six regions. The pattern we identified through the Hindi performance gap is thus not unique to Hindi; rather, it reflects a broader tendency in AI-mediated news retrieval: When confronted with non-English questions, models often route their information-seeking through globally indexed English-language sources. Those sources may report different figures, quotations, contextual details, or editorial emphases than the original local reporting, thus creating opportunities for factual divergence even when the underlying event is the same.
There are important downstream implications. When the same news event is queried, different chatbots ground their answers in materially different sources. This is a form of information fragmentation peculiar to AI-mediated access, distinct from the editorial selection effects that have always shaped news consumption. And it is shaped as much by legal and commercial arrangements as by retrieval engineering, on a layer largely invisible to the user receiving the answer.
 A Different Kind of Fragility
A Different Kind of Fragility
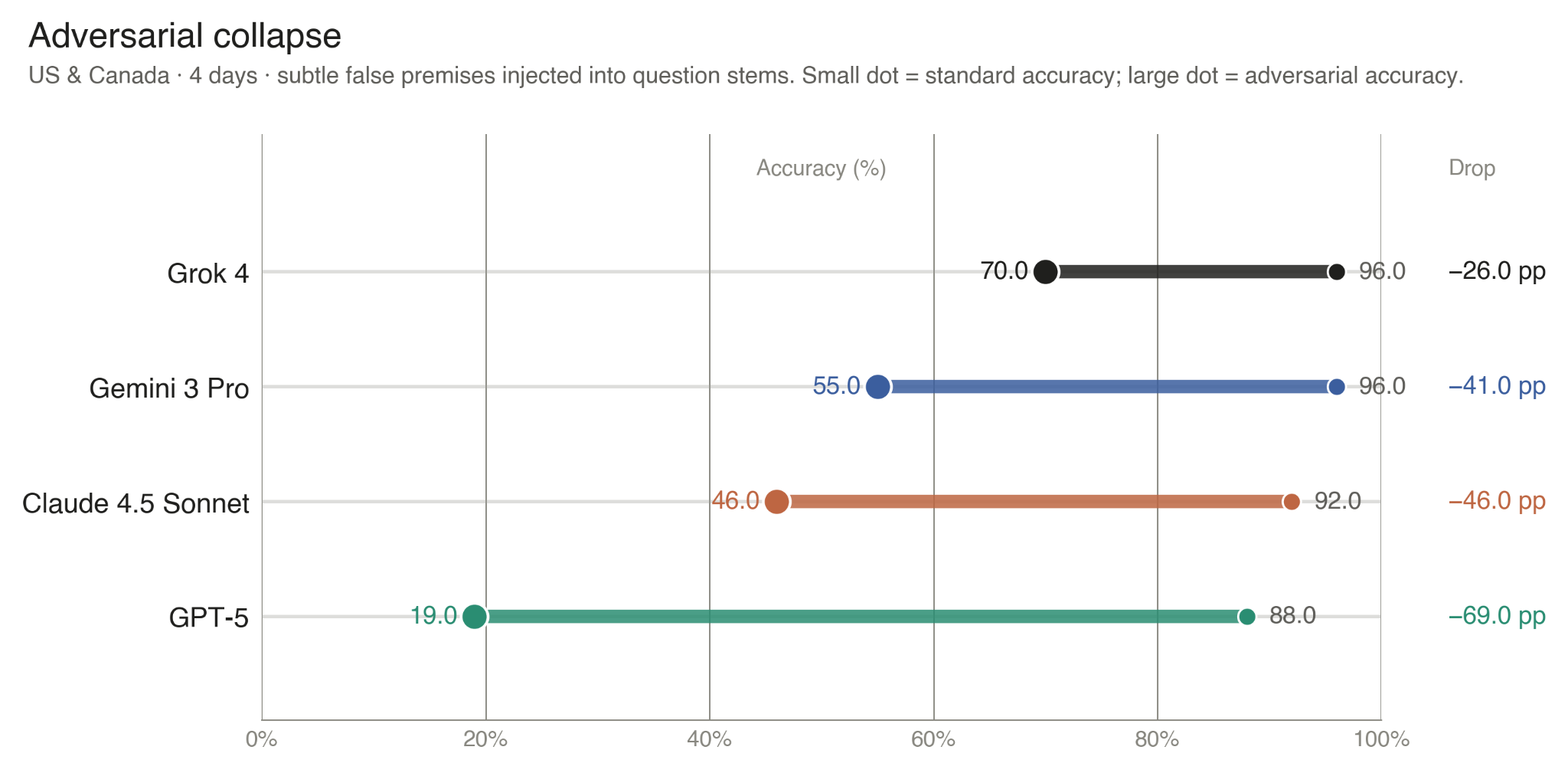
Reliability on well-formed questions is only part of the picture, however. Real-world users frequently ask imperfect questions: They misremember names, conflate events, or take a contested premise as given. To test how the systems handle this, we further constructed adversarial variants of the U.S. & Canada question set over four days. Each adversarial item introduced a single subtle factual alteration (e.g., a wrong attribution, a fabricated detail, a scope inversion) while preserving plausible question structure. A robust system should either flag the false premise or recover the verified facts despite the misleading framing.
Under favorable multiple-choice conditions, the four frontier models tested cluster within 8% (that is, 88–96%). Under adversarial conditions, the spread widens to 51%: Grok 4, for instance, retained 70.0% accuracy while GPT-5 fell to 19.0%.
A finer granular analysis separated two distinct capabilities. Detection asks whether the model explicitly flags or corrects the injected falsehood in its reasoning. Adversarial (or abstention) accuracy considers whether the final answer is correct. The two axes dissociated. Gemini 3 Pro, the strongest detector, flagged 80% of false premises but answered only 55% correctly. Claude 4.5 Sonnet detected 78% but answered 46% correctly. Grok 4, which detected only 59% of false premises, ranked first in adversarial accuracy because its retrieval pipeline often recovered the correct facts even without recognizing the false premise.
 Beyond Aggregate Accuracy
Beyond Aggregate Accuracy
Aggregate accuracy is a metric most visible to users and developers, but it does not surface where these systems quietly fail. The gaps that this study documents fall disproportionately on Hindi-language speakers (and likely others whose native language is sparsely indexed on the open web), on users who pose imperfect questions, and on the journalists whose reporting is consumed but rarely credited. Hindi accuracy was lowest not because models could not read Hindi, but because the retrieval infrastructure that fed them under-indexed Hindi-language journalism, favoring Western- and English-oriented sources. Citation patterns were starkly uneven, not because some systems retrieved better in any clean sense but because legal and commercial arrangements perhaps determine which publishers are reachable. Adversarial collapse from 88–96% to as low as 19% is a property of the same systems whose high numbers invite trust.
Three caveats about the study are worth mentioning. First, the study uses multiple-choice items; a parallel free-response validation showed a 16–17% drop in absolute accuracy, though model rankings remained stable across three independent LLM judge-annotators. Open-ended naturalistic queries would likely expose additional failure modes. Second, BBC News is a well-indexed, high-trust source; performance on less prominent outlets might plausibly be lower, and providers that comply with the BBC’s licensing and scraping restrictions are mechanically disadvantaged on this benchmark. Third, all queries originated from U.S.-based servers, which may amplify the Anglophone retrieval pivot for non-English regions.
Public-interest evaluation of AI news intermediaries should therefore measure and report more than aggregate accuracy. It should also measure retrieval fidelity across languages and regions, source attribution and its legal determinants, and robustness to the imperfect questions real users routinely pose. These dimensions are becoming increasingly important as AI-mediated access to news becomes widespread. A 2026 Reuters Institute survey, for instance, found that news executives are expecting a 43% decline in Google search traffic to publishers over three years. As more users encounter journalism through AI lenses rather than directly through publishers’ sites, differences in retrieval, attribution, and source selection will increasingly shape whose reporting reaches the general public, under what terms, and how.
The question is therefore no longer whether AI chatbots will serve as news intermediaries. They are already doing that. The more pressing and urgent question is whether users, journalists, and policymakers will have visibility into the dimensions on which these AI systems vary the most. Our results suggest that many of these consequential differences (including regional retrieval disparities, source-selection patterns, and susceptibility to imperfect or false premises) remain largely invisible, especially behind a single headline metric of accuracy. We hope that this study will contribute to broader conversations about both the promise and the risks of consuming today’s headlines through AI.
This work was partially supported by the Stanford Institute for Human-Centered AI.



